-
カテゴリ別 最新ニュース
-
2026-03-19
リリース
-
2026-01-21
イベント/セミナー
-
2026-01-07
経営/財務
-
2026-03-17
お知らせ
-
-
最新ニュース
-
2026/01
-
2025/11
-
2025/08
UPDATE (08/24)
-
2025/08
-
2025/03
UPDATE (04/03) -
2025/04
-
カテゴリ別 最新ニュース
2026-03-19
リリース
2026-01-21
イベント/セミナー
2026-01-07
経営/財務
2026-03-17
お知らせ
最新ニュース
2026/01
2025/11
2025/08
2025/08
2025/03
2025/04
2025/06/17
リリース
2025年6月17日
国際航業のフェローである島田 徹と理化学研究所 革新知能統合研究センターの岡谷 貴之インフラ管理ロボット技術チームリーダー(東北大学教授を兼務)、東京大学大学院 工学系研究科の全 邦釘特任准教授、筑波大学 システム情報系の永谷 圭司教授らの共同研究グループは、大規模言語モデル(LLM)を活用し、ドローンなどで撮影した土砂災害の画像から専門家レベルの分析を行うマルチモーダル人工知能(AI)システムを開発しました。
本研究成果は、土砂災害発生時の迅速かつ安全なリスク評価を可能にし、限られた専門家リソースを効率的に活用するための新たな枠組みを提供するものであり、今後の災害対応における意思決定支援の基盤になると期待されます。
共同研究グループは、専門家による解説音声を構造化データに変換し、大規模言語モデル(LLM)を用いて学習可能な形に整理。さらに、画像とテキストを統合的に扱うマルチモーダルAIを開発し、専門家に匹敵する解析と説明を実現しました。
本研究は、 “Computer-Aided Civil and Infrastructure Engineering” (Wiley)に掲載予定で、既に速報版がWEBに掲載されています。
https://onlinelibrary.wiley.com/doi/full/10.1111/mice.13482

地すべり災害の空撮画像から専門家レベルの分析を行うマルチモーダルAIシステム 活用イメージ
【背景】
気候変動の影響により、世界中で大規模な自然災害の発生頻度が高まっています。災害発生時には、被害の範囲、原因、および追加的なリスクを迅速かつ正確に評価することが命を救い、二次災害を防ぐために不可欠です。近年、高精度のデジタルカメラの普及や監視カメラネットワークの普及により、災害地域の画像データ収集は飛躍的に向上しました(図1)。
しかし現状では、災害発生箇所の高度な判断や予測ができるのは、十分な知識と経験を持つ専門家のみであり、広範囲に及ぶ大規模災害では、限られた数の専門家で即時の意思決定を行うことは困難です。さらに、これらの専門家は複数の責任を担っていることが多く、人員を効率的に配置することが難しい状況にあります。
特に土砂災害は、地形と地盤条件(素因)と降雨や地震などの自然現象(誘因)の複雑な相互作用によって発生します。航空画像は、特に表層土が移動して下層の地盤条件が露出した災害後の状況において、これらの素因に関する豊富な視覚情報を提供します。専門家はこれらの視覚的手がかりから地質構造や風化条件を解釈できますが、この高度に専門的な解釈プロセスは、自動化が困難な暗黙知を多く含んでいます。

図1 土砂災害の画像の例
本研究で開発したAIは「土砂災害の種類、原因、観察事項、将来リスクを説明してください」という固定の指示プロンプトと災害画像を与えると、土砂災害現場の分析結果を生成する仕組みとなっている 。図1の画像に対して、開発したAIは、災害タイプを正しく「Landslide」と識別し、原因を「人為的活動と自然侵食」と推測した。観察事項では「細長い山岳地域内の急斜面」「露出した岩石」などの特徴を正確に捉えており、将来リスクも「さらなる斜面崩壊と侵食の可能性」と妥当な予測を行った。
【研究手法と成果】
研究グループは、土砂災害を分析するAIシステムの開発において、次の3つの課題に取り組みました。
① 専門家の知識をAI訓練用のデジタルデータに変換する方法
② 限られたデータからの効果的な学習方法
③ AIシステムの評価方法
①の専門知識のデジタル化のために、研究グループは過去の土砂災害現場の画像を専門家に提示し、彼らの観察や分析を音声記録しました。これらの記録をテキストに変換し、「災害タイプ」(土砂災害の種類)、「原因」(災害の推定原因)、「観察事項」(画像から観察される複数の特徴や状態)、「将来リスク」(将来的に発生する可能性のあるリスク)という標準的な構造に整理しました。この標準形式は、AIモデルがより効果的に学習できるよう設計されています(②の取り組み)。
③については、2つの異なるアプローチでAIシステムを開発しました(図2)
1. VQA-LLMハイブリッド
画像から情報を抽出する視覚的質問応答(VQA)モデルと、その結果をもとに分析を行う大規模言語モデル(LLM)を組み合わせたアプローチ
2. マルチモーダル大規模言語モデル(MLLM)
画像エンコーダー、視覚プロジェクター、LLMからなり、画像と指示テキストを同時に処理するエンドツーエンドのアプローチ
これらのモデルは日本各地の土砂災害現場の画像68枚(データ拡張により136サンプル)を用いて訓練されました。評価では、従来のテキスト類似性指標に加え、大規模言語モデルを用いた意味的評価と専門家による評価も実施しました。AIによる判読結果の例を図3に示します。
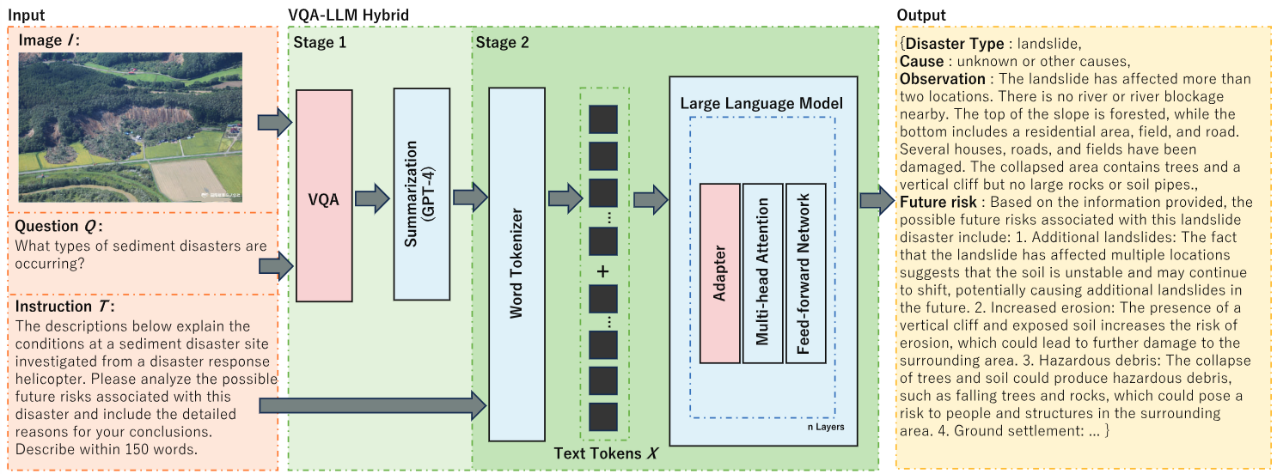
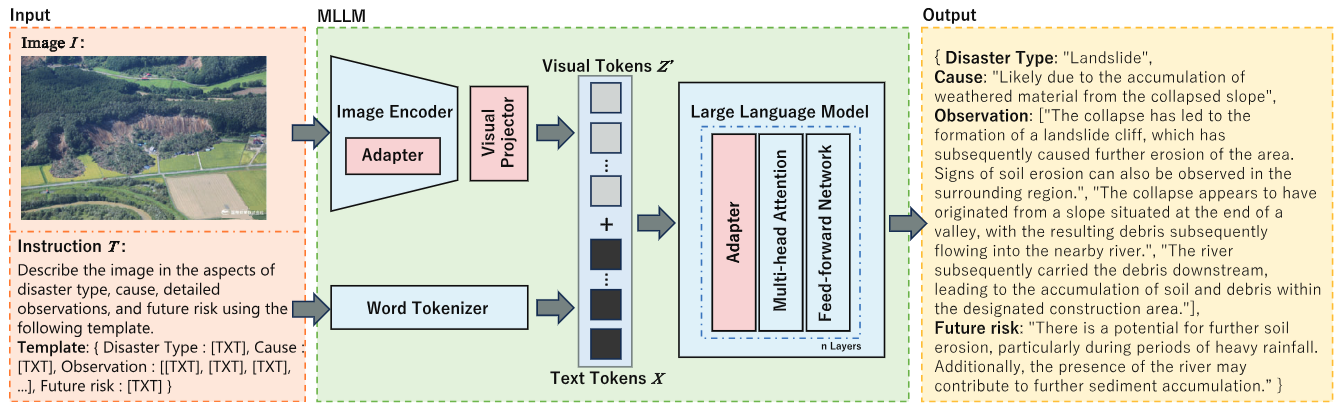
図2 開発した2つのモデル
上はVQA-LLMハイブリッド、下はマルチモーダル大規模言語モデル(MLLM)の構造を示す

図3 開発したAIによる土砂災害画像の判読結果
【今後の期待】
本研究で開発されたAIシステムは、以下のような実用的なシナリオでの活用が期待されます。
■ 大規模画像コレクションの自動スクリーニング
航空写真 や衛星から収集された大量の画像を自動処理し、高リスクの地すべりを特定・分類
■ 非専門家のための意思決定支援
消防士、警察、自治体職員など、地すべりに関する専門知識を持たない初動対応者に、現場で撮影した画像から専門家レベルの分析を提供
■ 専門家の効率向上
地すべりの専門家が多数の現場を効率的に評価する際の補助ツールとして機能
■ 時間的モニタリング
同一エリアの時系列画像を分析することで、条件の変化を追跡し、将来のリスク予測精度を向上
岡谷貴之チームリーダーは、「今回開発したAIシステムは、限られた専門家リソースしか利用できない特殊分野における災害対応を支援する重要な一歩です。この技術により、地すべり災害発生時の意思決定の迅速化と安全性の向上が期待できます」としています。
【本研究における国際航業の役割と今後の展望】
本研究は、データサイエンス、土木工学、ロボット工学といった複数の異なる学問分野の専門家による学際的な研究であるという特徴があります。国際航業は、土砂災害に関する画像データの収集方法や研究方法に関する企画・提案を行い、共同研究者との議論に貢献しました。また、当社 の熟練した地形判読技術者が「観察」し「分析」した記録を、教師データとなる地形判読結果(アノテーション)として提供しました。
今後、当社は本研究のような防災分野を革新する新技術の開発に引き続き取り組むと同時に、こうした新技術を実際の防災活動に活用する方法を模索します。
さらに、本研究で作成した教師データのような研究資源の公開などを通して、この研究分野全体の活性化を図り、事業を通じて社会に貢献してまいります。
<論文情報>
Multimodal artificial intelligence approaches using large language models for expert-level landslide image analysis
Kittitouch Areerob, Van-Quang Nguyen, Xianfeng Li, Shogo Inadomi, Toru Shimada, Hiroyuki Kanasaki, Zhijie Wang, Masanori Suganuma, Keiji Nagatani, Pang-jo Chun, Takayuki Okatani
Computer-Aided Civil and Infrastructure Engineering
10.1111/mice.13482
<研究支援>
本研究は、JST(ムーンショット型研究開発)JPMJMS2032及びJSPS科研費(20H05952, 23H00482, 21H01417)の支援を受けて行われました。
・理化学研究所 革新知能統合研究(AIP)センター プレスリリース
https://aip.riken.jp/news/20250617okatani-t_press_release/
・東北大学 COMPUTER VISION LAB.
https://www.vision.is.tohoku.ac.jp/?p=1738
国際航業株式会社 コーポレート統括本部 組織運営企画部 広報グループ
E-mail:info-kkc@kk-grp.jp
このページをシェア
![]()
Copyright © Kokusai Kogyo Co., Ltd. All Rights Reserved.